The rising popularity of deep learning created a healthy competition between deep learning frameworks. PyTorch and TensorFlow stand out as two of the most popular deep learning frameworks. The libraries are competing head-to-head for taking the lead in being the primary deep learning tool.
TensorFlow is older and always had a lead because of this, but PyTorch caught up in the last six months. There is a lot of confusion about making the right choice when picking a deep learning framework for a project.
This article compares PyTorch vs TensorFlow and provide an in-depth comparison of the two frameworks.
PyTorch vs. TensorFlow: An Overview
Both PyTorch and TensorFlow keep track of what their competition is doing. However, there are still some differences between the two frameworks.
Note: This table is scrollable horizontally.
| Library | PyTorch | TensorFlow 2.0 |
|---|---|---|
| Created by | FAIR Lab (Facebook AI Research Lab) | Google Brain Team |
| Based on | Torch | Theano |
| Production | Research focused | Industry-focused |
| Visualization | Visdom | Tensorboard |
| Deployment | Torch Serve (experimental) | TensorFlow Serve |
| Mobile Deployment | Yes (experimental) | Yes |
| Device Management | CUDA | Automated |
| Graph Generation | Dynamic and static mode | Eager and static mode |
| Learning Curve | Easier for developers and scientists | Easier for industry-level projects |
| Use Cases | Facebook CheXNet Tesla Autopilot Uber PYRO | Google Sinovation Ventures PayPal China Mobile |
1. Visualization
Visualization done by hand takes time. PyTorch and TensorFlow both have tools for quick visual analysis. This makes reviewing the training process easier. Visualization is also great for presenting results.
TensorFlow
Tensorboard is used for visualizing data. The interface is interactive and visually appealing. Tensorboard provides a detailed overview of metrics and training data. The data is easily exported and looks great for presentation purposes. Plugins make Tensorboard available for PyTorch as well.
However, Tensorboard is cumbersome and complicated to use.
PyTorch
PyTorch uses Visdom for visualization. The interface is lightweight and straightforward to use. Visdom is flexible and customizable. Direct support for PyTorch tensors makes it simple to use.
Visdom lacks interactivity and many essential features for overviewing data.
Follow our guides to install TensorFlow – How to Install TensorFlow on Ubuntu 18.04 or How to Install TensorFlow on CentOS
2. Graph Generation
There are two types of neural network architecture generation:
- Static graphs – Fixed layer architecture. The map generates first, then data is pushed through it.
- Dynamic graphs – Dynamic layer architecture. The map is defined implicitly with data overloading.
TensorFlow
TensorFlow used static graphs from the start. Static graphs allow distribution over multiple machines. Models are deployed independently of code. The use of static graphs made TensorFlow more production-friendly and flexible when working with new architectures.
TensorFlow added a feature that mimics dynamic graphs called eager execution. TensorFlow 2 runs on eager execution by default. Static graph generation is available when turning off eager execution.
PyTorch
PyTorch featured dynamic graphs from the start. This feature put PyTorch in competition with TensorFlow.
The ability to change graphs on the go proved to be a more programmer and researcher-friendly approach to neural network generation. Structured data and size variations in data are easier to handle with dynamic graphs. PyTorch also provides static graphs.
3. Learning Curve
The learning curve depends on previous experience and the end goal of using deep learning.
TensorFlow
TensorFlow is the more challenging library. Keras functions make TensorFlow is easier to use. Generally, TensorFlow is hard to comprehend for someone who is just starting with deep learning.
The reason behind this is the diverse functionality of TensorFlow. There are many features to explore and figure out. This is distracting and redundant for a beginner.
PyTorch
PyTorch is the easier-to-learn library. The code is easier to experiment with if Python is familiar. There is a Pythonic approach to creating a neural network in PyTorch. The flexibility PyTorch has means the code is experiment-friendly.
PyTorch is not as feature-rich, but all the essential features are available. PyTorch is simpler to start with and learn.
4. Deployment
Deployment is a software development step that is important for software development teams. Software deployment makes a program or application available for consumer use.
TensorFlow
TensorFlow uses TensorFlow Serving for model deployment. TensorFlow Serving is designed for production and industry environments in mind. Deployment is flexible and high-performing with a REST client API. TensorFlow Serving integrates well with Docker and Kubernetes.
PyTorch
PyTorch recently started tackling the problem of deployment. Torch Serve deploys PyTorch models. There is a RESTful API for application integration. The PyTorch API is extendible for mobile deployment. Torch Serve integrates with Kubernetes.
Torch Serve scales well for large models. Flask is the best option to quickly code up a REST API for serving simpler machine learning models.
5. Parallelism and Distributed Training
Parallelism and distributed training are essential for big data. The general metrics are:
- Speed increase – Ratio of a sequential model’s speed (single GPU) compared to the parallel model’s speed (multiple GPU).
- Throughput – The maximum number of images passed through the model per unit of time.
- Scalability – How the system handles workload increases.
Model accuracy does not depend on parallelism and distributed training. Accuracy is a comparison metric between two models that is hardware-independent. Parallel and distributed training compare computation speed between different platforms for the same model.
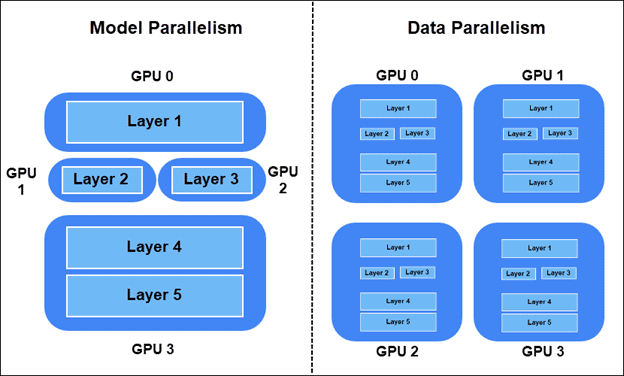
There are two ways to distribute the training workload:
- Model parallelism – Layers of the model split on different devices. Parts of the graph are used in training simultaneously.
- Data parallelism – All the devices have a copy of the whole model. Each device trains on different samples of data. The synchronous SGD (Stochastic Gradient Descent) method is preferred.
TensorFlow Model Parallelism
To place part of the model in a specific device in TensorFlow, use tf.device.
For example, split two linear layers on two different GPU devices:
import tensorflow as tf
from tensorflow.keras import layers
with tf.device(‘GPU:0’):
layer1 = layers.Dense(16, input_dim=8)
with tf.device(‘GPU:1’):
layer2 = layers.Dense(4, input_dim=16)
PyTorch Model Parallelism
Move parts of the model to different devices in PyTorch using the nn.Module.to method.
For example, move two linear layers to two different GPUs:
import torch.nn as nn layer1 = nn.Linear(8,16).to(‘cuda:0’) layer2 = nn.Lienar(16,4).to(‘cuda:1’)
TensorFlow Data Parallelism
To do synchronous SGD in TensorFlow, set the distribution strategy with tf.distribute.MirroredStrategy() and wrap the model initialization:
import tensorflow as tf strategy = tf.distribute.MirroredStrategy() with strategy.scope(): model = … model.compile(...)
After compiling the model with the wrapper, train the model as usual.
PyTorch Data Parallelism
For synchronous SGD in PyTorch, wrap the model in torch.nn.DistributedDataParallel after model initialization and set the device number rank starting with zero:
from torch.nn.parallel import DistributedDataParallel. model = ... model = model.to() ddp_model = DistributedDataParallel(model, device_ids=[])
6. Device Management
Massive changes in performance happen when managing devices. Both PyTorch and TensorFlow apply neural networks well, but the execution is different.
TensorFlow
TensorFlow automatically switches to GPU usage if a GPU is available. There is control over GPUs and how they are accessed. The GPU acceleration is automated. What this means is there is no control over memory usage.
PyTorch
PyTorch uses CUDA to specify usage of GPU or CPU. The model will not run without CUDA specifications for GPU and CPU use. GPU usage is not automated, which means there is better control over the use of resources. PyTorch enhances the training process through GPU control.
7. Use Cases for Both Deep Learning Platforms
TensorFlow and PyTorch were first used in their respective companies. Since becoming open source, there are many use cases outside of Google and Facebook too.
TensorFlow
Google researchers at Google Brain Team first used TensorFlow for Google research projects. Google uses TensorFlow for:
- Search results and autocompletion.
- Speech-to-text and voice technology.
- Image recognition and classification.
- Machine translation systems.
- Spam detection for Gmail.
There are many use cases outside of Google as well. For example:
- Sinovation Ventures – Disease classification and segmentation using images of retinas.
- PayPal – Fraud detection with deep transfer learning and generative modeling.
- China Mobile – Deep learning systems for problem detection in networks, automated cutover time windows prediction, and operation logs verification.
PyTorch
PyTorch was first used at Facebook by the Facebook AI Researchers Lab (FAIR). Facebook uses PyTorch for:
- Facial recognition and object detection.
- Spam filtering and fake news detection.
- Newsfeed automation and friend suggestion system.
- Speech recognition.
- Machine translation systems.
PyTorch is open source. There are now many use cases outside of Facebook, such as:
- CheXNet – Pneumonia probability scoring and chest X-Ray heatmap using convolutional neural networks.
- Tesla Autopilot – Real-time computer vision multitasking for autonomous vehicles.
- Uber AI Labs PYRO – Probabilistic programming language for deep probabilistic modeling. Prediction and optimization of matching customers with drivers, optimal routes, and next-generation intelligent vehicles.
Refer to our Knowledge Base for PyTorch and TensorFlow tutorials such as How to Check PyTorch Version and How To Check TensorFlow Version.
Should You Use PyTorch or TensorFlow?
PyTorch is the favorite option among programmers and scientific researchers. The scientific community prefers PyTorch when looking at the number of citations. With the recent deployment and production features, PyTorch is a great option when going from research to production.
Organizations and startups generally use TensorFlow. The deployment and production features give TensorFlow a good reputation in enterprise use cases. Visualization with Tensorboard shows an elegant presentation to clients as well.
PyTorch and TensorFlow are powerful deep learning libraries developing intensively. Today, there are more similarities than differences between the two and switching from one to the other is a seamless process.




