Introduction
NoSQL databases allow us to store vast amounts of data and access it at all times, from any location and device. However, it is difficult to decide which data modeling technique is best suited for your needs. Fortunately, there’s a data modeling technique for every use case.
In this tutorial we will cover all the different NoSQL data modeling techniques you can use when building your NoSQL database.

What is a NoSQL Data Model?
NoSQL or ‘Not Only SQL’ is a data model that starkly differs from traditional SQL expectations.
The primary difference is that NoSQL does not use a relational data modeling technique and it emphasizes flexible design. The lack of requirement for a schema makes designing a much simpler and cheaper process. That isn’t to say that you can’t use a schema altogether, but rather that schema design is very flexible.
Another useful feature of NoSQL data models is that they are built for high efficiency and speed in terms of creating up to millions of queries a second. This is achieved through having all the data contained within one table, and so JOINS and cross-referencing is not as performance heavy.
NoSQL is also unique in that it is horizontally scalable, compared to SQL which is only vertically scalable. With NoSQL you can simply use another shard, which is cheap, rather than buying more hardware, which is not.
Note: Horizontal scalability opens the possibility of using clusters of easily provisioned infrastructure, such Bare Metal Cloud, to host a complex NoSQL database for a wide range of enterprise use cases.
Four Types of NoSQL Databases
Generally speaking, there are four different types of NoSQL databases, with dozens of data models based on them:
Key-Value Store
Built specifically for high-performance requirements, and probably one of the most common data models, key-value stores use key values with pointers to store data.
This pointer is unique and links directly to a piece of information, which can be anything you’d like it to be. You could even use an empty string as a value key if you like, although there are upper limits to how big a value can be depending on the database.
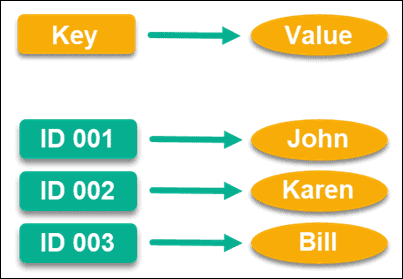
Interestingly enough, it was Amazon who originally helped get this data model off the ground, and they use it for DynamoDB. Given that they are one of the biggest online marketplaces in the world, you can see how high-performance this data model can be.
Document-Based Store
With SQL, XML and JSON tend to be tied together, which slows queries down and hampers the whole process. Since NoSQL doesn’t use the relational model, it doesn’t need to do that, which is where document-based stores come in.
All data is stored in one table, so there’s no need for cross-referencing and instead of storing information in a table, it’s stored in a document. While this is very similar to a key-value store, and can sometimes be considered under its umbrella, the difference is that document-based NoSQL generally has some form of encoding, such as XML.
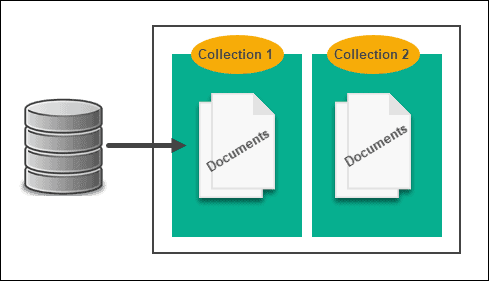
There’s an XML-specific NoSQL database that uses a document store. In fact, Strider CD uses MongoDB as a backing store.
Column-Based Store
This type of data model stores information in columns, rather than in rows which is more usual with SQL. Data is stored in columns, which are grouped into families, and these families are further grouped into more columns. This essentially creates a nearly limitless column nestling data model.
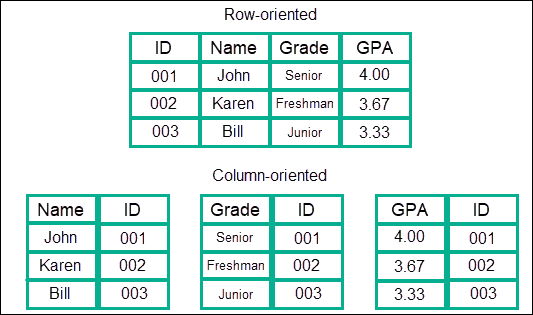
The benefit is that it offers blisteringly fast speeds compared to other models or NoSQL when it comes to searches. The data is treated as one continuous entry, and therefore there is no need for jumping across rows or different areas where the information is stored.
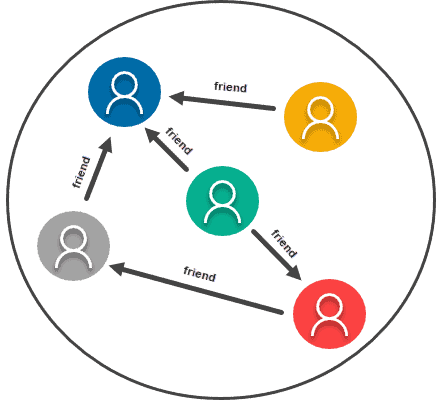
Graph-Based Store
Graph or network data models essentially treat the relationship between any two pieces of information as being just as important as the information itself. As such, this type of data model is really made for any information that you’d usually represent on a graph. It uses relationships and nodes, with the data being the information itself, and the relationship is formed between nodes.
How is Data Stored in NoSQL?
NoSQL data storage depends on which type of database you use. Since NoSQL doesn’t require a schema, there is no blueprint on how data should be stored, and therefore varies between databases.
Generally, there are two ways that NoSQL data storage functions:
- On-the-disk using B-Trees, with the top of it being permanently in RAM.
- In-memory where it’s all on RAM using RB-Trees and anything stored on the disc is just an append.
Schema Design for NoSQL
Since NoSQL databases don’t really have a set structure, development and schema design tends to be focused around the physical data model. That means developing for large, horizontally expansive environments, something that NoSQL excels at. Therefore, the specific quirks and problems that come with scalability are at the forefront.
As such, the first step is to define business requirements, as optimizing data access is a must, and can only be achieved by knowing what the business wants to do with the data. Your schema design should complement the workflows tied to your use case.
There are several ways to select the primary key, and ultimately that depends on the users themselves. That being said, some data might suggest a more efficient schema, especially in terms of how often that data is queried.
Note: NoSQL is flexible enough to alter it as you go along. Therefore, if you find that the first schema that you designed requires some tweaks to make user accessibility better, as well as provide additional optimization, that’s not an issue.
NoSQL Data Modeling Techniques
All NoSQL data modeling techniques are grouped into three major groups:
- Conceptual techniques
- General modeling techniques
- Hierarchy modeling techniques
Below, we will briefly discuss all NoSQL data modeling techniques.
Conceptual Techniques
There are a three conceptual techniques for NoSQL data modeling:
- Denormalization. Denormalization is a pretty common technique and entails copying the data into multiple tables or forms in order to simplify them. With denormalization, easily group all the data that needs to be queried in one place. Of course, this does mean that data volume does increase for different parameters, which increases the data volume considerably.
- Aggregates. This allows users to form nested entities with complex internal structures, as well as vary their particular structure. Ultimately, aggregation reduces joins by minimizing one-to-one relationships.
Most NoSQL data models have some form of this soft schema technique. For example, graph and key-value store databases have values that can be of any format, since those data models do not place constraints on value. Similarly, another example such as BigTable has aggregation through columns and column families. - Application Side Joins. NoSQL doesn’t usually support joins, since NoSQL databases are question-oriented where joins are done during design time. This is compared to relational databases where are performed at query execution time. Of course, this tends to result in a performance penalty and is sometimes unavoidable.
General Modeling Techniques
There are a five general techniques for NoSQL data modeling:
- Enumerable Keys. For the most part, unordered key values are very useful, since entries can be partitioned over several dedicated servers by just hashing the key. Even so, adding some form of sorting functionality through ordered keys is useful, even though it may add a bit more complexity and a performance hit.
- Dimensionality Reduction. Geographic information systems tend to use R-Tree indexes and need to be updated in-place, which can be expensive if dealing with large data volumes. Another traditional approach is to flatten the 2D structure into a plain list, such as what is done with Geohash.
With dimensionality reduction, you can map multidimensional data to a simple key-value or even non-multidimensional models.
Use dimensionality reduction to map multidimensional data to a Key-Value model or to another non-multidimensional model. - Index Table. With an index table, take advantage of indexes in stores that don’t necessarily support them internally. Aim to create and then maintain a unique table with keys that follow a specific access pattern. For example, a master table to store user accounts for access by user ID.
- Composite Key Index. While somewhat of a generic technique, composite keys are incredibly useful when ordered keys are used. If you take it and combine it with secondary keys, you can create a multidimensional index that is pretty similar to the above-mentioned Dimensionality Reduction technique.
- Inverted Search – Direct Aggregation. The concept behind this technique is to use an index that meets a specific set of criteria, but then aggregate that data with full scans or some form of original representation.
This is more of a data processing pattern than data modeling, yet data models are certainly affected by using this type of processing pattern. Take into account that random retrieval of records required for this technique is inefficient. Use query processing in batches to mitigate this problem.
Hierarchy Modeling Techniques
There are a seven hierarchy modeling techniques for NoSQL data:
- Tree Aggregation. Tree aggregation is essentially modeling data as a single document. This can be really efficient when it comes to any record that is always accessed at once, such as a Twitter thread or Reddit post. Of course, the problem then becomes that random access to any individual entry is inefficient.
- Adjacency Lists. This is a straightforward technique where nodes are modeled as independent records of arrays with direct ancestors. That’s a complicated way of saying that it allows you to search nodes by their parents or children. Much like tree aggregation though, it is also quite inefficient for retrieving an entire subtree for any given node.
- Materialized Paths. This technique is a sort of denormalization and is used to avoid recursive traversals in tree structures. Mainly, we want to attribute the parents or children to each node, which helps us determine any predecessors or descendants of the node without worrying about traversal. Incidentally, we can store materialized paths as IDs, either as a set or a single string.
- Nested Sets. A standard technique for tree-like structures in relational databases, it’s just as applicable to NoSQL and key-value or document databases. The goal is to store the tree leaves as an array and then map each non-leaf node to a range of leaves using start/end indexes.
Modeling it in this way is an efficient way to deal with immutable data as it only requires a small amount of memory, and doesn’t necessarily have to use traversals. That being said, updates are expensive because they require updates of indexes. - Nested Documents Flattening: Numbered Field Names. Most search engines tend to work with documents that are a flat list of fields and values, rather than something with a complex internal structure. As such, this data modeling technique tries to map these complex structures to a plain document, for example, mapping documents with a hierarchical structure, a common difficulty you might encounter.
Of course, this type of work is pain-staking and not easily scalable, especially as the nested structures increase. - Nested Documents Flattening: Proximity Queries. One way to solve the potential problems with the Numbered Field Names data modeling technique is to use a similar technique called Proximity Queries. These limit the distance between words in a document, which helps increase performance and decrease query speed impact.
- Batch Graph Processing. Batch graph processing is a great technique for exploring the relationships up or down for a node, within a few steps. It is an expensive process and doesn’t necessarily scale very well. By using Message Passing and MapReduce we can carry out this type of graph processing.
Conclusion
NoSQL data modeling techniques are very useful, especially since a lot of programmers aren’t necessarily familiar with the flexibility of NoSQL. The specifics vary since NoSQL isn’t so much a singular language like SQL, but rather a set of philosophies for database management. As such, data modeling techniques, and how they are applied, vary wildly from database to database.
Don’t let that put you off though, learning NoSQL data modeling techniques is very helpful, especially when it comes to designing a scheme for a DBM that doesn’t actually require one. More importantly, learn to take advantage of NoSQL’s flexibility. Don’t have to worry as much about the minutiae of schema design as you would with SQL.
